안녕하세요 이승혁입니다.
지난 포스팅까지 단일행 함수, 복수행 함수를 간단하게 실습해보았습니다.
이번 시간에는 실질적으로 데이터 분석을 용이하게 해주는 함수들에 대해 실습을 진행해보도록 하겠습니다.
※ 데이터 분석 함수
데이터 분석을 용이하게 해주는 함수
- rank
- dense_rank
- ntile
- listagg
- lead
- lag
- pivot
- nupivot
- 누적데이터를 출력하는 함수
ㆍ데이터 분석 함수 - rank
순위를 출력하는 함수
rank() over(order by 기준)
실습 1. 나이가 높은 순서대로 순위를 부여해보기
select replace(ename,substr(ename,-2,1),'*') ename,age,rank() over(order by age desc) 순위
from emp11;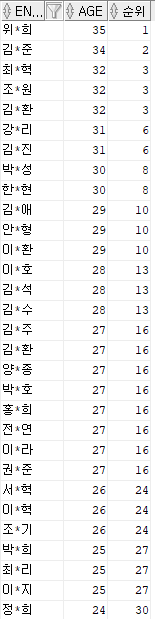
실습 2. 1등만 출력해보기
1. 순위 출력
select replace(ename,substr(ename,-2,1),'*') ename,age,rank() over(order by age desc) 순위
from emp11;2. 서브쿼리 사용
select *
from(
select replace(ename,substr(ename,-2,1),'*') ename,age,rank() over(order by age desc) 순위
from emp11
)
where 순위=1; 
실습 3. 입사일이 빠른 순서대로 순위 부여해보기
select ename,hiredate,rank() over(order by hiredate asc) 순위
from emp;
실습 4. 특정 월급의 순위 알아내기
select rank(2450) within group(order by sal desc) 순위
from emp;
rank 뒤 괄호 안에 원하는 값, within group(정렬) 검색을 수행하면, 해당 값의 순위가 출력됩니다.
ㆍ데이터 분석 함수 - dense_rank()
공동 순위 다음 순위를 차등 부여하는 함수
dense_rank() over(order by 기준칼럼)
일반 rank() 함수는 같은 값이 있는 경우 모든 행의 개수를 포함하여 다음 순위를 정합니다.

실습5. dense_rank()
select replace(ename,substr(ename,-2,1),'*') ename, dense_rank() over(order by age desc) 순위
from emp11;
ㆍ데이터 분석 함수 - dense_rank()
결과를 가로로 출력하는 함수
listagg(데이터,'구분자') within group(order by 기준)
실습 6. listagg, 각 부서번호에 속한 사원의 이름을 가로로, 오름차순 정렬해보기
select deptno, listagg(ename,',') within group(order by ename) 이름
from emp
group by deptno;
실습 7. 통신사별 이름을 가로로 오름차순 정렬해보기
select lower(telecom) telecom, listagg(replace(ename,substr(ename,-2,1),'*'),',') within group(order by ename) 이름
from emp11
group by lower(telecom);
실습 8. 실습 7번에 나이도 같이 출력해보기
select lower(telecom) telecom, listagg(replace(ename,substr(ename,-2,1),'*')||'('||age||')',',') within group(order by ename) 이름
from emp11
group by lower(telecom);
ㆍ데이터 분석 함수 - ntile()
등급을 출력하는 함수
ntile(나눌등급) over(order by 기준)
실습 9. 월급을 4개 등급으로 나누어서 출력해보기
select ename, sal, ntile(4) over (order by sal desc) 등급
from emp;

※ 설명
ntile(4) = 0 ~ 25% : 1등급
25 ~ 50% : 2등급
50 ~ 75% : 3등급
75 ~ 100% : 4등급
ㆍ데이터 분석 함수 - lag & lead
lag : 바로 전 행을 출력하는 함수
lead : 바로 다음 행을 출력하는 함수
lag(데이터,범위)
lead(데이터,범위)
범위가 1이라면 하나 전 행을, 2이면 두개 전 행을 출력합니다.
실습 10. 월급을 오름차순으로 이전행, 다음행을 출력해보기
select ename, sal, lag(sal,1) over(order by sal asc) lag_이전행,
lead(sal,1) over(order by sal asc) lead_다음행
from emp;

실습 11. 입사일을 오름차순으로 정렬한 후 입사 간격을 출력해보기
select ename, hiredate, hiredate-lag(hiredate) over (order by hiredate asc) 입사간격
from emp;

ㆍ데이터 분석 함수 - pivot
행(row)을 열(column)로 출력하는 함수
pivot( 그룹함수() for 기준칼럼 in (기준데이터))
실습 12. 세로 출력과 가로 출력 비교해보기
1. 세로출력
select deptno, sum(sal)
from emp
group by deptno;
2. 가로 출력
select *
from ( select deptno,sal
from emp )
pivot(sum(sal) for deptno in(10,20,30));
※ pivot 문 사용할 때 주의사항
- from절 서브쿼리에 필요한 칼럼만 기술한다.
- from절 서브쿼리에 함수를 사용했으면 반드시 별칭 !!
※ pivot 사용을 위해선 컬럼 이름과, 컬럼의 기준 값(10,20,30)들을 알고 있어야 한다.
※ pivot을 사용하기 전
select sum(decode(deptno,10,sal) ) as "10",
sum(decode(deptno,20,sal) ) as "20",
sum(decode(deptno,30,sal) ) as "30"
from emp;pivot이 상당히 까다롭다고 생각할 수 있지만, pivot 이전의 표현 방법을 알고 있다면 조금 노력해서
pivot 함수를 사용할 가치가 있다고 생각합니다.
실습 13. pivot 이전 코딩 방식으로 부서번호별, 직업별 총 월급의 합을 출력해보기
select deptno,sum(decode(job,'ANALYST',sal,0)) as "ANALYST",
sum(decode(job,'CLERK',sal,0)) as "CLERK",
sum(decode(job,'MANAGER',sal,0)) as "MANAGER",
sum(decode(job,'PRESIDENT',sal,0)) as "PRESIDENT",
sum(decode(job,'SALESMAN',sal,0)) as "SALESMAN"
from emp
group by deptno;
ㆍ데이터 분석 함수 - unpivot
unpivot vs pivot
가로 --------> 세로 세로 -----> 가로
칼럼 --------> 데이터 데이터 -----> 칼럼
※ unpivot 실습 데이터
create table order2
( ename varchar2(10),
bicycle number(10),
camera number(10),
notebook number(10) );
insert into order2 values('SMITH', 2,3,1);
insert into order2 values('ALLEN',1,2,3 );
insert into order2 values('KING',3,2,2 );
commit;
실습 14. unpivot 각 사원별 구매한 품목을 세로로 확인해보기
select *
from order2
unpivot( EA for item in (BICYCLE, CAMERA, NOTEBOOK));

EA - 해당 칼럼이 가지고 있던 각 데이터(2,3,1)를 표현할 칼럼명
item - 칼럼명(BICYCLE,CAMERA,NOTEBOOK)을 합쳐 새롭게 표현할 칼럼명
ㆍ데이터 분석 함수 - 누적 데이터 출력
누적치를 출력해 확인할 수 있어야 한다.
실습 15. 월급의 누적치를 오름차순으로 확인해보기
select ename, sal, sum(sal) over (order by sal rows
between unbounded preceding and current row) 누적치
from emp;
※ 설명 : unbounded preceding : 첫 번째 행
unbounded following : 마지막 행
current row : 현재 행
누적치는 현재 행을 포함한 이전 행까지의 값의 누적을 나타냅니다.
실습 16. 통신사별 나이의 누적치를 확인해보기
select telecom, replace(ename,substr(ename,-2,1),'*') ename, age, sum(age) over( partition by telecom
order by age rows
between unbounded preceding
and current row) 누적치
from emp11;
partition by ___ 코드를 추가 작성해 나눌 기준을 명시해 줍니다.
실습 16번으로 포스팅을 마치겠습니다.
다음 포스팅에서는 여러 테이블의 칼럼을 하나의 결과로 볼 때 사용하는 JOIN 문법을 다루어 보겠습니다.
감사합니다.
'프로그래밍 > SQL' 카테고리의 다른 글
| SQL-14 ) 서브쿼리(Sub Query) - 2 : SQL, SQLD, SQLD자격증, 서브 쿼리, 오라클 (0) | 2020.11.05 |
|---|---|
| SQL-13) 서브 쿼리(Sub Query) : SQL문, SQLD, SQLD 자격증, DB , database (0) | 2020.10.30 |
| SQL-12) JOIN 문법 -2 , ansi join : sqld, mysql, sql 자격증,DB 손해보험 (0) | 2020.10.29 |
| SQL-11) JOIN 문법 - 1 (오라클 조인 문법) (0) | 2020.10.28 |
| SQL-9) group by, having , 함수(function) - 5 (0) | 2020.10.27 |
| SQL-8) 함수(function) - 4 (2) | 2020.10.26 |
| SQL-7) 함수(function) - 3 (0) | 2020.10.25 |
| SQL-6) 함수(function) - 2 (0) | 2020.10.23 |