
안녕하세요 이승혁입니다.
이번 시간은 다섯 가지 데이터베이스 오브젝트 중 index(인덱스)에 대해 다루어 보도록 하겠습니다.
※ index
검색 속도를 높이는 데이터 베이스의 오브젝트 입니다.
데이터는 매일 테라급으로 쌓이고 있기 때문에 테이블의 크기가 점점 대용량이 되어가고 있습니다.
그래서 데이터를 검색할 때 시간이 많이 걸리게 됩니다.
검색 속도를 높이기 위해서 특별한 기술이 필요한데 그게 SQL 튜닝이고,
SQL 튜닝을 잘 하려면 인덱스(index)를 잘 이해해야 합니다.
ㆍ 인덱스 없이 일반 검색쿼리에서의 실행 계획을 확인합니다.
예제) 월급이 1600인 사원의 이름과 월급을 출력하시오
set autot on
select ename, sal
from emp
where sal=1600;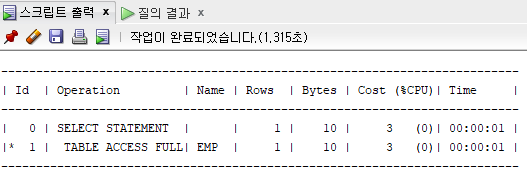
TABLE ACCESS FULL : 테이블 전체를 조회한다.
즉, 해당 조건에 맞는 컬럼을 찾아도 끝까지 검색한다.
인덱스가 없다는 것은 우리가 책을 찾을 때 목차가 없이 책 전체를 뒤지는 것과 같습니다.
ㆍ 사원 테이블의 월급에 인덱스를 생성하고, 실행계획을 확인합니다.
create index emp_sal_idx -- 현업에서 인덱스 명시하기 위한 인덱스명으로 사용
on emp(sal);
set autot on
select ename, sal
from emp
where sal=1600;
실행 계획을 읽는 순서는 ID 2 -> 1 -> 0 입니다.
INDEX RNAGE SCAN : 목차를 사용한 접근을 합니다.
TABLE ACCESS BY INDEX ROWID BATCHED : ROWID를 찾아 검색한다.
※ rowid : 테이블의 행의 물리적 주소
file# + block# + row# 로 구성되고, 유니크한 값을 갖는다.
ㆍ rowid 확인해보기
select rowid,ename,sal,job
from emp;
단일 데이터 검색 시 rowid에 의한 데이터 검색이 가장 빠른 속도를 냅니다.
ㆍ index의 구조를 확인해보기
인덱스는 구조가 컬럼명 + rowid의 구조로 구성되어 있습니다.
인덱스의 컬럼명은 ascending하게 정렬되어 있습니다.
select sal,rowid
from emp
where sal>0;

index 사용을 위해 조건절을 걸어주어야 한다.
order절을 사용해주지 않아도 정렬되어서 출력되는데 이는 index를 통해 데이터를 읽어왔기 때문이다.
위에서 생성한 index를 사용한 것을 실행 계획을 통해 알 수 있다.
※ 그림으로 이해하기
다음 실행 코드에 대해 full table scan / index range scan을 비교하겠습니다.
select ename, sal, job
from emp
where ename = 'SCOTT';1. full table scan
전체 데이터를 읽으므로 해당하는 데이터를 찾더라도 끝까지 다 검색을 수행해야 한다.
2. index range scan

where절의 ename을 기준으로 rowid를 검색하고 , 다시 그 ROWID를 사용해 해당하는 데이터 행을 출력한다.
※ SQL 튜닝
ㆍ index가 있음에도 full table scan을 하는 경우 ?
set autot on
select ename, sal, job
from emp
where sal*12=36000;
이유는 where절의 좌변이 가공되었기 때문이다.
즉 sal 자체에 인덱스를 걸었지만, sal*12라는 조건을 사용하기 때문이다.
다음과 같이 변경하여 인덱스를 통한 검색이 가능하다.
set autot on
select ename, sal, job
from emp
where sal=36000/12;
ㆍ order by 절 ?
대용량 데이터의 경우 데이터를 정렬하는 데 시간이 많이 걸릴 수 있다.
따라서 order by 절이 자주 사용되거나, 필요한 칼럼을 인덱스로 지정한다.
ㆍ 오라클 힌트 ?
SQL 실행계획을 만드는 옵티마이져(optimizer)에게 실행을 '이렇게 했으면 좋겠다' 라고 실행 계획에 관여하는
명령어 입니다.
힌트 사용 : select /*+ 힌트 */ col, col, …
index_asc(tanme index_name) ? tname 테이블에 index_name 인덱스를 ascending 스캔한다.
index_desc(tname index_name) : tname 테이블에 index_name 인덱스를 descending 스캔한다.
ㆍ 함수 기반 인덱스 ?
위의 예시처럼 where절의 조건을 가공하지 않기 위해서, 다음과 같이 함수 기반 인덱스를 작성합니다.
create index emp11_telecom_func
on emp11(lower(telecom));
telecom 칼럼은 kt, lg, sk 세 가지로 이루어져 있습니다.
그런데 Kt,KT 와 같이 다른 문자를 하나의 kt로 검색할 때, where절에 가공을 해야합니다.
-> where lower(telecom)='kt';
이는 가공 과정을 통해 index를 사용할 수 없게 됩니다.
따라서 인덱스를 생성할 때 함수를 적용해 함수 기반 인덱스를 사용합니다.
ㆍ 인덱스 리스트 확인하기
select A.table_name, A.index_name,A.column_name
from all_ind_columns A
where A.table_name LIKE '%EMP%';
이번 시간에는 인덱스에 대해서 알아보았습니다.
다음 시간에는 데이터베이스 오브젝트 시퀀스에 대해 알아보도록 하겠습니다.
감사합니다.
'프로그래밍 > SQL' 카테고리의 다른 글
| SQL - 칼럼 데이터 타입 변경하기 (0) | 2020.12.08 |
|---|---|
| SQL-19) DDL 문장 , table , view : SQL, SQLD (0) | 2020.12.08 |
| SQL-18) TCL - commit, rollback, savepoint : SQL,SQLD,SQLD 자격증 (0) | 2020.11.10 |
| SQL-17) DML - Insert, update, delete, merge : SQL, SQLD, SQLD 자격증, Oracle (0) | 2020.11.09 |
| SQL-16) exist , with , 계층형 질의 : SQl, SQLD 자격증, ADsP, 함수 (0) | 2020.11.05 |
| SQL-15)집합연산자 - UNION, UNION ALL, INTERSECT, MINUS : sqld, sqld 자격증 (0) | 2020.11.05 |
| SQL-14 ) 서브쿼리(Sub Query) - 2 : SQL, SQLD, SQLD자격증, 서브 쿼리, 오라클 (0) | 2020.11.05 |
| SQL-13) 서브 쿼리(Sub Query) : SQL문, SQLD, SQLD 자격증, DB , database (0) | 2020.10.30 |