
딥러닝과 다르게 머신러닝은 데이터의 전처리가 중요합니다.
데이터의 품질이 분석 모델의 성능을 좌우합니다.
데이터의 평균, 분포 등을 파악한 후 누락 데이터, 중복 데이터와 같은 이상 데이터를 처리합니다.
이번 시간에는 데이터의 결측치와 중복된 값을 전처리하는 과정을 실습해보도록 하겠습니다.
사용 데이터는 파이썬 내장 라이브러리 seaborn의 titanic 데이터 입니다.
※ titanic 데이터 ?
탑승객의 생존 여부를 예측하는 데이터 입니다.
나이, 성별, 가족 수, 객실 등급 등의 데이터가 존재하며 자주 사용되는 데이터 입니다.
다음은 seaborn에서 사용 가능한 데이터셋의 목록입니다.
import seaborn as sns
print(sns.get_dataset_names())
### 누락 데이터 처리하기
누락 데이터는 값이 존재하지 않는 데이터 입니다.
NaN(Not a Number) 값으로 표시되며 null값이라고 생각하면 됩니다.
전체 데이터에서 누락 데이터가 차지하는 비율이 아주 작다면 영향도를 고려해 제거합니다.
10~20% 등 어느 정도의 비중을 차지한다면 적당한 값으로 치환하여 사용하는 것이 모델 성능을 보장할 것입니다.
누락 데이터가 너무 많은 칼럼은 중요도를 판단해 제거할지, 치환할지 결정합니다.
## 누락 데이터 확인
※ Pandas DataFrame 결측치 확인
1. isnull() : null 값인 데이터는 True를 반환
2. notnull() : null 값인 데이터는 False를 반환
import seaborn as sns
ti=sns.load_dataset('titanic')
ti.isnull()
ti.notnull()

두 함수의 기능은 같습니다.
서로 반대의 결과를 출력합니다.
3. isnull().sum()
isnull() 함수의 결과 데이터 프레임에 sum() 함수를 적용했습니다.
파이썬은 True = 1 , False = 0 으로 치환되기 때문에 isnull 함수와 사용해서 null 데이터 개수를 구합니다.

age(나이) 데이터에 177개의 결측치가 존재합니다.
embarked(탑승 항구 약자) 데이터에 2개 결측치가 존재합니다.
deck(데크) 데이터에 688개 결측치 존재합니다.
embark_town(탑승 항구 풀네임) 데이터에 2개 결측치가 존재합니다.
※ deck(데크) 데이터는 검색을 통해 다음과 같은 표시임을 확인했습니다.

## 누락 데이터 열 제거
1. 열 제거
dropna() 함수를 사용해서 제거합니다.
axis , thresh 옵션을 사용하겠습니다.
axis = 1 옵션을 주어 열 데이터임을 표현합니다.
thresh = 500 옵션을 주어 결측치 개수가 500개 이상인 데이터만 삭제합니다.
688개의 결측치를 갖는 deck 열이 삭제 되었습니다.
원본 데이터 프레임을 변경하기 위해서는 inplace=True 옵션을 함께 사용합니다.

## 누락 데이터 행 치환
누락된 데이터의 값을 다른 값으로 치환하는 방법입니다.
여러가지 방법이 있지만 실습은 다음 세가지 방법을 사용하겠습니다.
1. 평균 값으로 치환하기
2. 최빈 값으로 치환하기
3. 이웃 데이터 값으로 치환하기
# 평균 값 치환
mean() 함수를 사용해 평균 값을 구한 후, fillna() 함수를 사용해 해당 칼럼의
결측 데이터를 평균 값으로 치환했습니다.
inplace=True 옵션을 통해 원본 데이터를 변경합니다.
mean_data=ti['age'].mean()
ti['age'].fillna(mean_data,inplace=True)
ti.isnull().sum()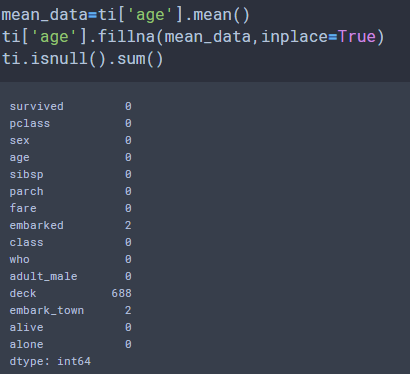
# 최빈 값 치환
가장 많이 나온 데이터로 치환합니다.
24세가 가장 많은 것으로 확인 되었습니다.
24세로 177개의 결측 데이터를 치환합니다.
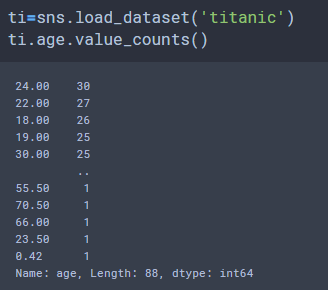
most_age=ti.age.value_counts().idxmax()
print(most_age)
ti.age.fillna(most_age,inplace=True)
ti.isnull().sum()
# 이웃 데이터 값 치환
누락 데이터를 바로 앞의 값으로 치환합니다.
혹은 누락 데이터의 바로 뒤 값으로 치환합니다.
1. 앞의 값으로 치환 : fillna(method='ffill')
2. 뒤의 값으로 치환 : fillna(method='bfill')

이 외에도 나이를 종속 변수로 사용해 회귀를 사용한 값으로 치환 한다던가,
중앙 값을 사용 하는 등의 여러가지 방법이 있습니다.
여러 방법을 사용해보고 가장 나은 결과를 사용하는 것이 좋습니다.
### 중복 데이터 처리하기
중복 데이터는 삭제하여 불필요한 학습을 추가하지 않도록 합니다.
## 중복 데이터 확인
duplicated 함수를 사용해서 중복 데이터를 확인합니다.
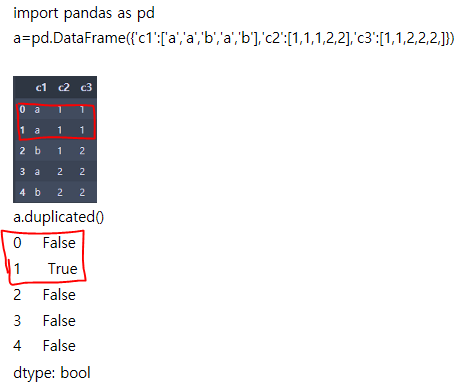
타이타닉 데이터 셋에는 107개의 중복 데이터가 존재합니다.
ti=sns.load_dataset('titanic')
ti.duplicated().sum()
## 중복 데이터 제거
drop_duplicates() 함수를 사용해서 제거합니다.
마찬가지로 원본 객체에 적용하기 위해서는 inplace 옵션을 사용해야 합니다.
ti.drop_duplicates(inplace=True)
ti.duplicated().sum()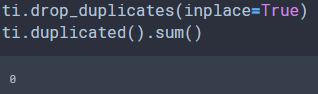
오늘은 데이터 전처리 중 결측 데이터와 중복 데이터를 처리하는 방법을 알아보았습니다.
다음 시간에도 이어서 데이터를 전처리하는 실습을 진행하겠습니다.
읽어주셔서 감사합니다.
'프로그래밍 > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 전처리 | 범주형 데이터 | 구간 분할 | 더미 변수 (0) | 2021.02.11 |
|---|---|
| [Pandas] 데이터 전처리 | 데이터 표준화 | 단위 변환 | 자료형 변환 (0) | 2021.02.10 |
| [Pandas] 데이터 시각화 | Matplotlib | 파이차트 | 박스그래프 (0) | 2021.02.04 |
| [Pandas] 데이터 시각화 | Matplotlib | 히스토그램 | 산점도 (4) | 2021.02.01 |
| [Pandas] 데이터 시각화 | Matplotlib | 면적 그래프 | 막대 그래프 (0) | 2021.01.30 |
| [Pandas] 데이터 시각화 | Matplotlib | 그래프 꾸미기 (1) | 2021.01.11 |
| [Pandas] 데이터 시각화 | 판다스 내장 그래프 (2) | 2021.01.06 |
| Pandas - 통계 함수 max min corr (2) | 2021.01.05 |