
안녕하세요 이승혁입니다.
오늘은 판다스의 내장 그래프를 이용해 데이터를 시각화 하겠습니다.
데이터를 분석해보면서 시각화가 정말 중요하단 것을 느꼈습니다.
내가 이해하기에도, 남을 이해시키기에도 가장 좋은 방법이었습니다.
데이터를 간략하고 예쁘게 시각화 할 수 있는 능력은 데이터 분석가에게 필수라고 생각합니다.
## 판다스 내장 그래프
판다스는 데이터를 시각화 하는 라이브러리인 Matplotlib의 기능을 일부분 내장하고 있습니다.
별도로 import 하지 않아도 간단하게 데이터를 그래프로 표현할 수 있습니다.
| Option | 종류 | Option | 종류 |
| 'line' | 선 그래프 | 'kde' | 커널 밀도 그래프 |
| 'bar' | 막대 그래프 - 수직 | 'area' | 면적 그래프 |
| 'barh' | 막대 그래프 - 수평 | 'pie' | 원형 그래프 |
| 'his' | 히스토그램 그래프 | 'scatter' | 산점도 그래프 |
| 'box' | 박스 그래프(사분위수) | 'hexbin' | 고밀도 산점도 그래프 |
제가 데이터 분석을 해보면서 자주 사용했던 그래프 위주로 간단한 실습만 진행해 보겠습니다.
판다스 시각화 참고 사이트
pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html#plot-formatting
Visualization — pandas 1.2.0 documentation
These functions can be imported from pandas.plotting and take a Series or DataFrame as an argument. Andrews curves Andrews curves allow one to plot multivariate data as a large number of curves that are created using the attributes of samples as coefficien
pandas.pydata.org
# 데이터 확인
import pandas as pd
df=pd.read_excel('d:\판다스 실습\실습데이터2.xlsx')
df
# line option , 선 그래프
Datafram.plot() 의 기본(default) 그래프는 선 그래프입니다.
figsize : 그래프 크기 조정
fontsize : x축 , y축 라벨 크기 조정
import pandas as pd
df=pd.read_excel('d:\판다스 실습\실습데이터2.xlsx')
df=df.iloc[[0,5],3:]
df.index=['South','North']
#데이터 일부 확인
print(df[['1991','1992','1993','1994','1995']])
df.plot()
시간에 따른 변화를 보기 위해 데이터 프레임을 전치(transpose) 하겠습니다.


# bar option , 막대 그래프 - 수직
선 그래프가 아닌 다른 종류의 그래프를 사용하려면 kind 옵션을 사용합니다.
수직 막대 그래프는 kind='bar' 옵션을 통해 구현합니다.
df.transpose().plot(kind='bar',figsize=(20,15),fontsize=30)
# barh option , 막대 그래프 - 수평
막대그래프를 수직이 아닌 수평으로 시각화해주는 옵션입니다.
df.plot(figsize=(30,20),fontsize=30)
# hist option , 히스토그램 그래프
데이터 값을 일정 구간으로 나눕니다.
구간에 속하는 데이터의 개수를 막대 그래프 형태로 나타냅니다.
df.transpose().plot(kind='hist',figsize=(10,4),fontsize=15)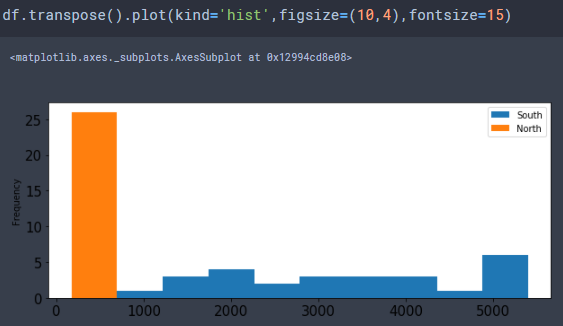
y축은 빈도(frequency) , x 축은 일정 데이터 범위 입니다.
약 800정도의 단위로 나뉜 것 같습니다.
# scatter option, 산점도 그래프
두 변수 간의 관계를 나타내는 그래프 입니다.
지난시간에 포스팅한 상관관계를 확인할 때 사용합니다.
2021/01/05 - [프로그래밍/Pandas] - Pandas - 통계 함수 max min corr
Pandas - 통계 함수 max min corr
산술 데이터를 갖는 DataFrame의 열에 통계 함수를 적용해 결과를 확인합니다. 특정 열에 적용할 수 있습니다. # mean - 평균값 산술 데이터를 갖는 각 열에 대한 평균값을 시리즈 객체로 반환 # median
lsh-story.tistory.com
mpg & displacement 두 변수는 강한 음의 상관관계를 가지고 있었습니다.
산점도 그래프를 통해 확인해보겠습니다.

실제로 x축의 mpg가 증가 할 때, y축의 displacement 값은 점점 감소하는 경향을 띄고 있습니다.
# box plot - 박스 그래프
사분위수 범위를 확인해 데이터의 분포 파악합니다.
이상치(Outlier) 유무를 확인할 때 사용할 수도 있습니다.


mpg 칼럼에는 이상치가 1개 존재합니다.
< 이상치 기준 >
Q1 : 하한 사분위수 , 25%
Q2 : 중앙값 , 50 %
Q3 : 상한 사분위수 , 75%
IRQ = Q3 - Q1
상단 이상치 > Q3 + 1.5 * IRQ
하단 이상치 < Q1 - 1.5 * IRQ
# pie option , 원형 그래프
데이터에 속하는 값의 크기를 기준으로 차지하는 비율을 나타냅니다.
그래서 문자형 데이터인 job을 사용할 때는 value_counts() 메소드를 사용했습니다.
groupby 메소드와 count 열을 생성해 사용하기도 합니다.

'프로그래밍 > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 시각화 | Matplotlib | 파이차트 | 박스그래프 (0) | 2021.02.04 |
|---|---|
| [Pandas] 데이터 시각화 | Matplotlib | 히스토그램 | 산점도 (4) | 2021.02.01 |
| [Pandas] 데이터 시각화 | Matplotlib | 면적 그래프 | 막대 그래프 (0) | 2021.01.30 |
| [Pandas] 데이터 시각화 | Matplotlib | 그래프 꾸미기 (1) | 2021.01.11 |
| Pandas - 통계 함수 max min corr (2) | 2021.01.05 |
| Pandas - 데이터 분석 (4) | 2021.01.02 |
| Pandas - 판다스 연산 (6) | 2020.12.30 |
| Pandas - Index 활용 (2) | 2020.12.29 |