
안녕하세요.
이승혁입니다.
판다스를 사용해서 csv, 엑셀, Json 등의 파일을 읽어옵니다.
DataFrame 형태의 데이터를 확인할 수 있는 코드를 실습해 보겠습니다.
## 파일 읽기(read)
1. csv - pd.read_csv('경로/파일명')
2. excel - pd.read_excel('경로/파일명)
3. Json - pd.read_json('경로/파일명')
4. html - pd.read_html('경로/파일명')
## 파일 저장하기(save)
1. csv - pd.to_csv('경로/파일명')
2. excel - pd.to_excel('경로/파일명)
3. 하나의 액셀, 여러 데이터프레임 - pd.ExcelWriter('경로/파일명')
4. Json - pd.to_json('경로/파일명')
import pandas as pd
# 경로 지정
address='d:\\판다스 실습\\'
# csv 파일 읽기(read)
df_csv=pd.read_csv(address+'emp2.csv')
# excel 파일 읽기(read)
df_excel=pd.read_excel(address+'emp2.xlsx')
# Json 파일 저장(save)
df_csv.to_json(address+'emp2.json')
# 2개 데이터프레임 excel로 저장
writer=pd.ExcelWriter(address+'2DataFrame.xlsx')
df_csv.to_excel(writer,sheet_name='csv DataFrame')
df_excel.to_excel(writer,sheet_name='excel DataFrame')
writer.close()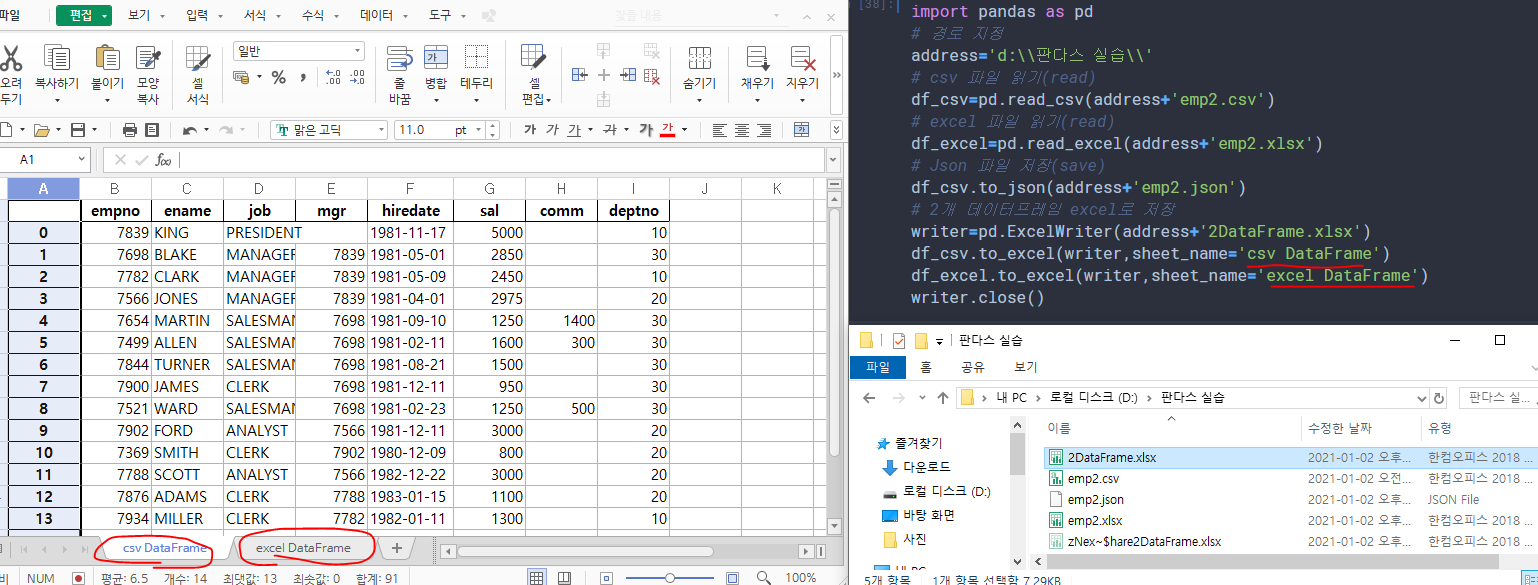
코드를 실행하여 파일을 읽어 봤습니다.
또 데이터프레임을 다양한 형태의 파일로 저장해 보았습니다.
## 데이터 확인하기
1. df.head(n)
2. df.tail(n)
3. df.info()
4. df.describe()
5. df.shape
6. df.count()
7. df[col].value_count()
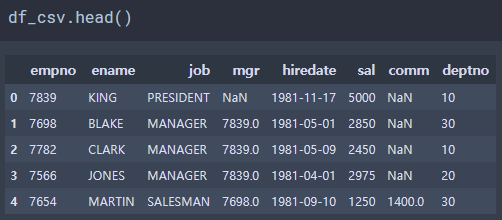
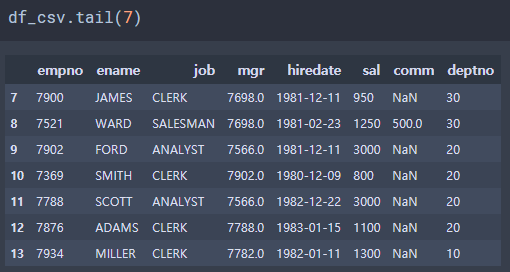
# df.head(n) & df.tail(n)
head - 첫 n 개의 데이터를 출력
tail - 마지막 n 개의 데이터를 출력
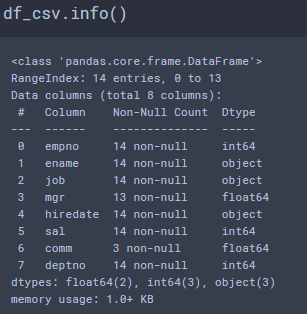
# df.info()
DataFrame의 기본 정보를 확인합니다.
클래스 유형, 행 인덱스 구성, 열 이름 종류 및 개수
각 열의 자료형 및 개수, 메모리 할당량
# df.describe()
DataFrame 기술 통계 정보를 요약합니다.
숫자 데이터를 갖는 열에 대한 개수, 평균, 표준편차, 최대 최소값, 사분위수 값을 출력합니다.
include='all' 옵션을 통해 문자열에 대한 정보도 확인합니다.
top : 최빈값 , freq: 빈도수, unique : 고유값 개수


# df.shape
DataFrame의 형상을 확인합니다.
행 개수, 열 개수를 쌍으로 반환합니다.

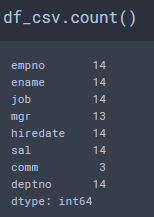
# df.count()
DataFrame 각 열의 데이터 개수를 시리즈 객체로 반환합니다.
Info 명령어와 달리 시리즈 객체로 반환해 다시 사용할 수 있습니다.
NaN 값은 제외한 개수만 반환합니다.
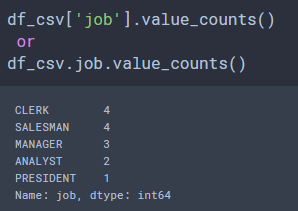
# df.value_count()
시리즈 객체의 고유값(unique value)의 개수를 확인합니다.
DataFrame 객체의 각 열은 시리즈 객체입니다.
따라서 다음과 같이 사용할 수 있습니다.
※ 위 그림을 그래프로 나타내기


데이터 결과를 사용해 간단하게 시각화 작업을 진행해 보았습니다.
읽어주셔서 감사합니다.
'프로그래밍 > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 시각화 | Matplotlib | 면적 그래프 | 막대 그래프 (0) | 2021.01.30 |
|---|---|
| [Pandas] 데이터 시각화 | Matplotlib | 그래프 꾸미기 (1) | 2021.01.11 |
| [Pandas] 데이터 시각화 | 판다스 내장 그래프 (2) | 2021.01.06 |
| Pandas - 통계 함수 max min corr (2) | 2021.01.05 |
| Pandas - 판다스 연산 (6) | 2020.12.30 |
| Pandas - Index 활용 (2) | 2020.12.29 |
| Pandas - Dataframe 열 , 행 , 값 (0) | 2020.12.29 |
| Pandas - Pandas Dataframe (0) | 2020.12.28 |