판다스 시리즈 , 판다스 데이터프레임에는 인덱스가 있습니다.
이를 활용해서 데이터를 검색, 정렬 할 수 있습니다.
데이터를 구분해주고 찾을 수 있게 해주는 인덱스를 활용하는 방법을 알려드립니다.
### 특정 열(column)을 행(row) 인덱스로 설정
set_index() 메소드를 사용합니다.
데이터 프레임의 특정 열을 행 인덱스로 설정합니다.
원본 데이터를 바꾸려면 inplace=True 옵션을 사용합니다.
print(df)
index_math=df.set_index(['수학'])
print(index_math.loc['50'])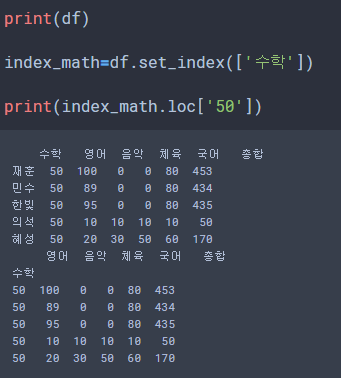
loc 인덱서를 사용해 데이터를 찾을 수 있습니다.
※ 잘못된 인덱스 설정
인덱스는 각각의 데이터를 구별 할 수 있어야 합니다.
즉, 각각 다른 데이터를 갖는 것이 기본이라고 할 수 있습니다.
위 예제처럼 '50' 인덱스를 출력했는데 모든 데이터 나오는 것을 볼 수 있습니다.
## 멀티 인덱스(Multi Index)
set_index() 메소드를 사용해서 두 개의 열을 인덱스로 사용할 수 있습니다.
multi_index_df=df.set_index(['수학','영어'])
print(multi_index_df,'\n')
print('멀티 인덱스의 인덱스 --\n',multi_index_df.index)
multi_index_df.loc[(50,100)]
### 행 인덱스 재배열
reindex() 메소드 사용
원본 데이터를 변경하려면 inplace=True 옵션을 사용한다.
새로운 데이터를 행 인덱스로 사용할 경우 NaN
fill_value를 사용해서 값을 지정합니다. 이때 반드시 스칼라 값이어야 합니다.
ndf=df.reindex(['경운','태은','건희','진욱'],fill_value='New!')
ndf
원래 데이터에 추가하려면 다음과 같이 진행합니다.
new_index2=['경운','태은','건희','진욱']
new_index=list(df.index)+new_index2
print('새로운 행 인덱스 : ',new_index)
new_df=df.reindex(new_index,fill_value='new!')
new_df
### 행 인덱스 초기화
reset_index()를 사용해 정수형 인덱스로 초기화
이때 인덱스는 열로 이동합니다.
new_df.reset_index()
### 행 인덱스 기준 정렬
sort_index() 행 인덱스 기준으로 값을 정렬합니다
ascending = True 오름차순 정렬
ascending = False 내림차순 정렬
new_df.sort_index(ascending=True)
new_df.sort_index(ascending=False)


### 특정 열의 값으로 정렬하기
sort_value('by'=열) 메소드를 사용해서 특정 열에 따라 데이터 프레임을 정렬합니다.
ascending = True 오름차순 정렬
ascending = False 내림차순 정렬
new_df=df.reindex(new_index,fill_value=10)
new_df.sort_values(by='수학',ascending=True)
new_df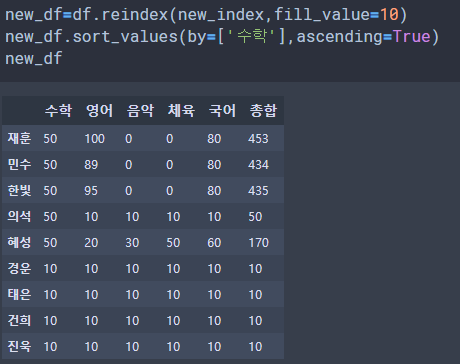
### NaN ??
Not a Number의 약자로 데이터 값이 비어있는 경우입니다.
0이아닌 아무값도 채워지지 않은 상태입니다.

따로 값을 지정해주지 않아서 비어있다는 표시입니다.
연산 수행 시 NaN과 연산을 진행하면 결과도 NaN이 나오게 됩니다.
# NaN 확인하기
ㆍ DataFrame.isnull() - DataFrame 원소의 NULL(NaN) 데이터를 True or False로 나타냅니다.
ㆍ DataFrame.isnull().sum() - True or False 값을 각 1 or 0으로 치환하여 값을 확인합니다.
각 칼럼의 NaN 개수를 확인할 때 사용합니다.
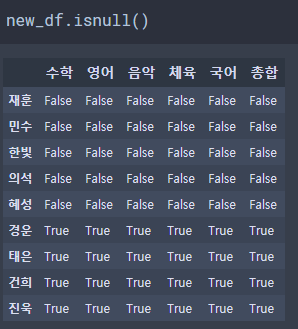
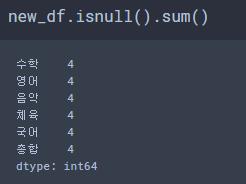
# NaN 처리하기
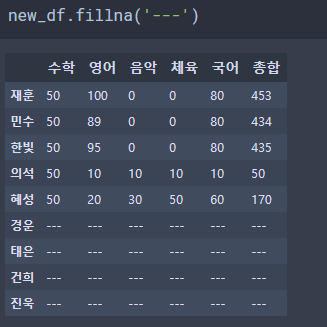
ㆍ DataFrame.fillna('data') - DataFrame의 NaN 값을 채울 데이터를 사용합니다.
ㆍ DataFrame.dropna() - DataFrame의 NaN 을 가진 데이터를 삭제합니다.
option
opti n axis=1 : 열 데이터 제거
axis=0 : 행 데이터 제거
inplace=True : 원본 데이터 변경

'프로그래밍 > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 시각화 | Matplotlib | 그래프 꾸미기 (1) | 2021.01.11 |
|---|---|
| [Pandas] 데이터 시각화 | 판다스 내장 그래프 (2) | 2021.01.06 |
| Pandas - 통계 함수 max min corr (2) | 2021.01.05 |
| Pandas - 데이터 분석 (4) | 2021.01.02 |
| Pandas - 판다스 연산 (6) | 2020.12.30 |
| Pandas - Dataframe 열 , 행 , 값 (0) | 2020.12.29 |
| Pandas - Pandas Dataframe (0) | 2020.12.28 |
| Pandas - Pandas Series (2) | 2020.12.28 |