안녕하세요 이승혁입니다.
이번 포스팅은 판다스의 자료구조 series , dataframe 중 dataframe에 대해 해보겠습니다.
※ pandas series ?
인덱스 : 값의 1:1 대응으로 이루어진 1차월 배열 자료구조였습니다!
인덱스는 정수형 인덱스, 인덱스 이름 두 가지 종류가 있고
인덱스를 사용해 데이터 값을 한개 , 여러개, 혹은 범위를 지정하여 구할 수 있었습니다.
시리즈를 생성할 때 인덱스를 부여할 수 도 있고 , 인덱스 속성을 사용해 나중에 리스트로 지정할 수도 있었습니다.
### Pandas Dataframe
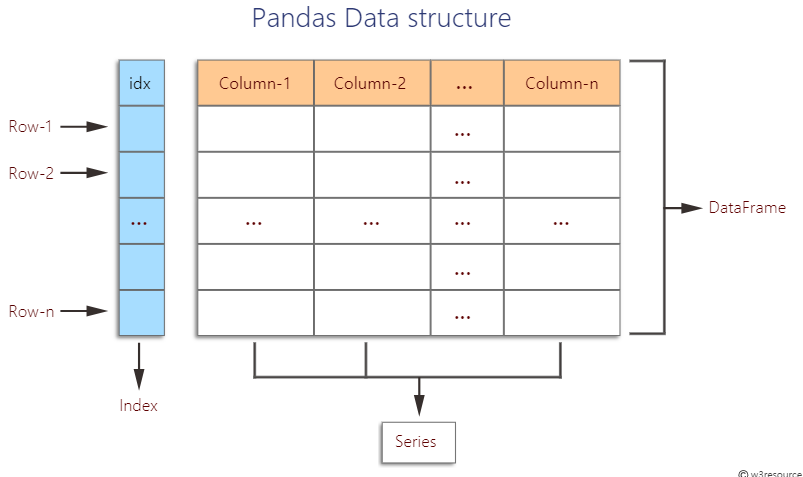
판다스 데이터 프레임은 2차원 배열입니다.
흔히 생각하시는 엑셀의 구조를 생각하시면 됩니다.
오라클과 같은 관계형 데이터베이스(RDBMS)등 여러 분야에 걸쳐 사용되는 자료형입니다.
판다스 데이터 프레임은 통계 패키지 R의 데이터프레임에서 유래했다고 합니다!
열(column) : 공통된 속성을 갖는 데이터
행(row) : 개별 관측 대상 데이터
즉 , 열은 각각의 속성(이름, 나이, 성별, 생년월일)을 나타냅니다.
행은 개개인별 자료를 나타냅니다( Scott, James, ... )
import pandas as pd
data={'이름':['이승혁','이승규','김정환','송수한'],'성별':['남','여','남','여'],
'거주지':['서울','수원','부산','대구'],'나이':[27,28,29,30]}
df=pd.DataFrame(data)
print(type(df))
print(df)
데이터 프레임 생성은 pandasd의 DataFrame 함수를 사용합니다. ( 대소문자 구별 o )
값(values)으로 리스트를 갖는 딕셔너리를 인자로 Dataframe을 만듭니다.
키(key) : column 이름
값(values) : column 데이터
## index , columns
2차원 배열 형태의 데이터 구조인 리스트, 튜플을 데이터프레임으로 바꿔 봤습니다.
이 때 인덱스와 열 이름 속성을 직접 지정할 수 있습니다.
import pandas as pd
data=[['남','서울',28],['여','수원',28],['남','부산',29],['여','대구',30]]
df=pd.DataFrame(data,index=['승혁','승규','정환','수한'],
columns = ['성별','거주지','나이'])
print(type(df))
print(df)
이 경우 리스트의 각 원소가 행으로 바뀌었습니다.
딕셔너리 구조로 데이터 프레임을 만들었을 때는 값(values)들은 열(column)이 된 것과 차이를 갖습니다.
Series 객체는 index 속성으로 값에 접근이 가능했습니다.
Datafram 객체도 index 속성으로 행 접근, columns를 사용해 열 이름 접근을 할 수 있습니다.

Series와 마찬가지로 리스트로 index, columns를 나중에 따로 지정할 수도 있습니다!
# rename index, rename columns
index, column의 이름을 다시 부여할 수 있습니다.
Dataframe 객체의 rename 함수를 사용하면 됩니다.
df.rename(index={'승혁':'혁','승규':'규','정환':'환','수한':'한'},inplace=True)
df.rename(columns={'성별':'sex','거주지':'address','나이':'age'},inplace=True)
df
inplace=True : 원본 변경 옵션
기본값(default)은 inplace=False 입니다.
# drop row / column
행, 열 삭제는 데이터 정제 및 관리에 필수입니다.
Dataframe 객체의 drop 함수에 인자로 행 인덱스, 배열, 열 이름 을 사용합니다.
# 열 이름으로 삭제, axis = 1 (세로 데이터) , inplace= False
print(df.drop('age',axis=1))
# 행 인덱스로 삭제, axis = 0 (가로데이터) , inplace = False
print(df.drop('혁',axis=0))
# 열 배열로 삭제, axis = 0 (가로데이터) , inplace = False
print(df.drop(['sex','age'],axis=1))
# 행 배열로 삭제, axis = 0 (가로데이터) , inplace = False
print(df.drop(['혁','규'],axis=0))
inplace = True 옵션을 부여하지 않아서 원본 데이터(df)는 변경되지 않습니다.
위의 예제를 연속해서 사용할 수 있는 것도 inplace=False 옵션이 기본으로 사용되기 때문입니다.
# 행 선택( loc, iloc)
행 데이터를 선택할 때는 loc, iloc 인덱서를 사용합니다!
loc : 인덱스 이름 , 범위 지정시 끝까지 포함
iloc : 정수 인덱스 , 범위 지정시 끝 미포함


# 열(column) 선택
데이터 프레임의 열 이름을 사용해 선택합니다.
두 가지 방법을 사용합니다.
1. 대괄호 안 '열이름'
2. Dataframe.'열이름'
3. 대괄호 안 리스트 ['열이름','열이름']

# 원소 선택
[행 인덱스, 열 이름] 좌표를 사용해 원소를 선택합니다.
" 1개 행 + 2개 이상 열
or
2개 이상 행 + 1개 열 "
--> Series 객체 반환

" 2개 이상 행 + 2개 이상 열 "
--> Dataframe 객체 반환

정수 인덱스를 사용하려면 iloc을 사용하시면 됩니다.
##### Dataframe Reference
https://pandas.pydata.org/docs/reference/frame.html
DataFrame — pandas 1.2.0 documentation
Flags Flags refer to attributes of the pandas object. Properties of the dataset (like the date is was recorded, the URL it was accessed from, etc.) should be stored in DataFrame.attrs. Flags(obj, *, allows_duplicate_labels) Flags that apply to pandas obj
pandas.pydata.org
'프로그래밍 > Pandas' 카테고리의 다른 글
| [Pandas] 데이터 시각화 | Matplotlib | 그래프 꾸미기 (1) | 2021.01.11 |
|---|---|
| [Pandas] 데이터 시각화 | 판다스 내장 그래프 (2) | 2021.01.06 |
| Pandas - 통계 함수 max min corr (2) | 2021.01.05 |
| Pandas - 데이터 분석 (4) | 2021.01.02 |
| Pandas - 판다스 연산 (6) | 2020.12.30 |
| Pandas - Index 활용 (2) | 2020.12.29 |
| Pandas - Dataframe 열 , 행 , 값 (0) | 2020.12.29 |
| Pandas - Pandas Series (2) | 2020.12.28 |